Wonton Soup: Proof Structures Under Interventions
wonton-soup is our intervention harness for proof-search experiments. The core question is simple:
when we perturb a solver’s search process, does it return to the same proof structure, or settle into a different one?
We run wild-type and intervention sweeps over deterministic theorem samples, capture full search artifacts (*_history.json, *_mcts_tree.json, *_graph.json, *_comparison.json), and compare outcomes across seeds, tactics, providers, and backends.

1. What We’re Looking For
We treat proof search as a stochastic process over structured states.
- A perturbation can be a blocked tactic or tactic family, a seed change, or a policy/scheduler change.
- A response can be recovery to the same structural family or migration into a different attractor.
- The object of study is not only solve rate; it is the shape and stability of search trajectories.
This is why we log enough structure to replay and compare runs months later under fixed configuration.
2. Inspirations and Framing
Three threads from the Diverse Intelligence research program motivate this setup.
Search efficiency as a measurable quantity
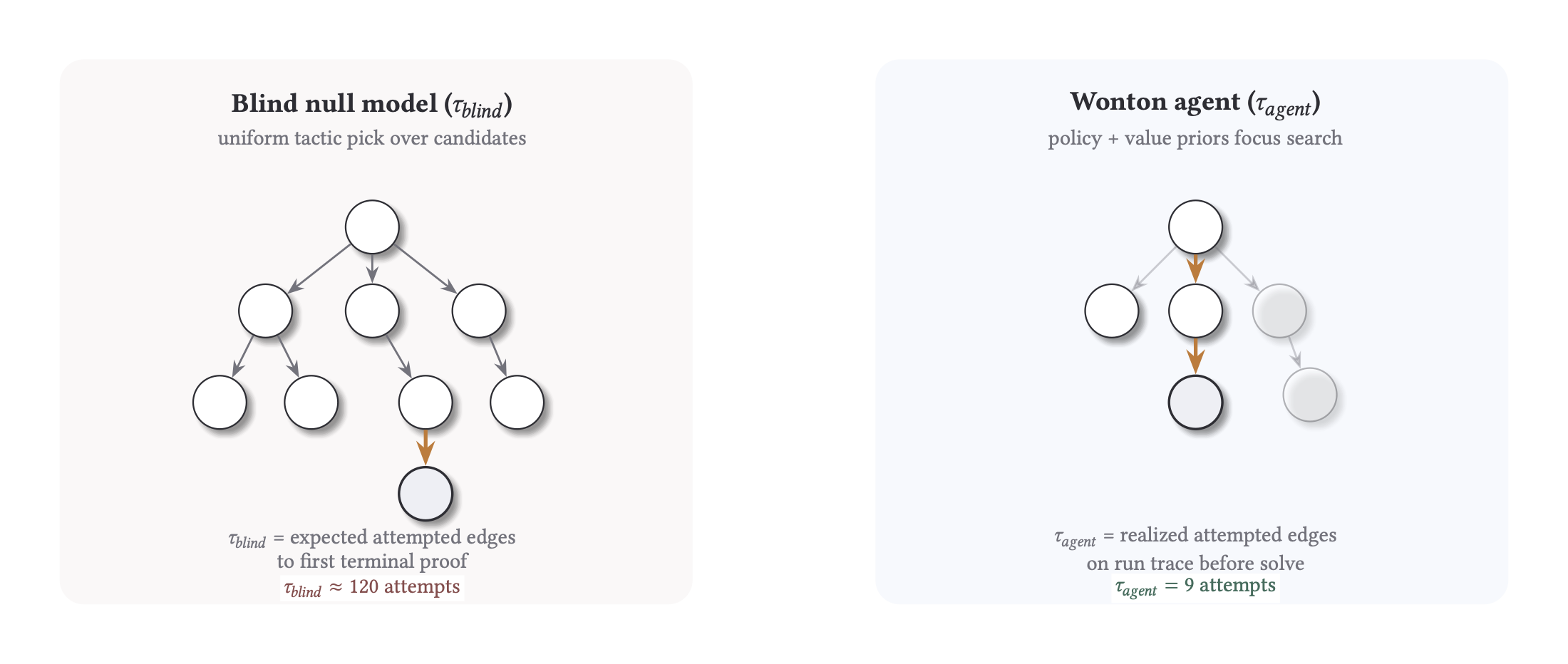
Chis-Ciure and Levin (2025) formalize biological intelligence as search efficiency in multi-scale problem spaces. Their central metric is the of the ratio between the cost of a random walk and that of the observed agent: how many orders of magnitude of work does a directed policy save over maximal-entropy search? Even under conservative assumptions, they show that organisms as simple as amoebae navigating chemical gradients operate hundreds to sextillions of times more efficiently than a blind baseline.
We borrow this framing directly. Our metric is the same log-ratio, applied to proof search: is the expected edge count for a null policy over the tactic action surface, is the observed count, and . A positive means the solver is exploiting structure in the problem space rather than brute-forcing it.
Local lesions, global behavioral readout
Zhang, Goldstein, and Levin (2024) reframe classical sorting algorithms as models of morphogenesis. Rather than treating algorithms as fixed computational procedures, they let each array element exert minimal local agency and implement sorting policies from the bottom up. The key finding is what happens under perturbation: when elements are “damaged” and cannot execute perfectly, the decentralized approach outperforms traditional implementations. Arrays with defective elements sort themselves more reliably than top-down implementations facing the same errors. The system exhibits unexpected competencies never explicitly programmed, including the ability to temporarily reduce local progress in order to navigate around a defect.
This is the template for our intervention protocol. We block one tactic or tactic family from a known solution path and rerun. The question is the same one Zhang et al. ask of their self-sorting arrays: does the system reroute around the lesion and still reach the goal, or does it collapse? And if it reroutes, is the resulting structure the same or different?
Pattern-level invariants under perturbation
Levin (2022) introduces the TAME framework for understanding cognition across radically different substrates. The core insight is a deep symmetry between problem-solving in anatomical, physiological, transcriptional, and behavioral spaces: the same patterns of multi-scale competency appear regardless of whether the substrate is a cell colony, a regenerating planarian, or a neural network. TAME argues that what matters is not whether a particular mechanism is present, but whether a behavioral structure persists under perturbation across scales.
We adopt this as our primary object of study. In the same veing, we ask whether the proof-search trajectory belongs to the same structural family as the wild-type run. Basin analysis, GED families, and attractor clustering are all ways of asking the TAME question in a formal-methods setting: is the pattern invariant, or did the perturbation push the system into a genuinely different attractor?
Mapping to proof search
In proof search, we try and have these three threads converge: block parts of tactic space, rerun under controlled budgets, and measure how structure changes. We then have:
- quantifies efficiency relative to blind.
- GED quantifies structural distance from wild-type.
- Basin analysis quantifies whether the system has one stable attractor or many.
Together, they let us ask whether a proof-search process exhibits the kind of robust, multi-path competency that Levin and collaborators study in biological systems, or whether it is brittle and path-dependent.
3. Harness and Corpus Design
Corpus management is incredibly important for us, both to have the necessary data to run these experiments, but also to make sure they are easily reproducible and stretch what our solver setup is capable of.
wonton-soup treats corpus and run configuration as first-class artifacts. Corpus builds are manifest-backed and run configs are snapshot-pinned. All downstream analysis reads those artifacts directly, which keeps the baseline fixed while we perturb one axis of behavior.
We also separate validity from capability. Gate A checks that an item is structurally processable for the chosen backend and schema contract. Gate B checks whether the provider and search policy can do meaningful work on that valid slice under the configured budget. Intervention studies run on slices that pass both gates, so failure modes are easier to interpret.
Deterministic selection (--sample with --seed) is how we ensure replayability. If you rerun later with the same corpus ref and selector inputs, you should recover the same theorem slice and comparable outputs.
Run-level schemas complete the provenance contract with run_config.json, run_status.json, and summary.json.gz being responsible for postprocess, lake extraction, and cross-run audits.
What is fixed per comparison run
- Corpus reference plus build provenance (
manifest.json, item ordering, hash identity). - Selection procedure (
--sample,--seed,--offset,--limit) and resulting theorem slice. - Search budget and core execution knobs (mode, iteration budget, intervention declaration).
- Analysis-facing artifact contract (
run_config.json,run_status.json,summary.json.gz, theorem subartifacts).
4. Search Core: Centralized and Distributed MCTS
The search core is one algorithmic family with two execution modes, not two unrelated systems. Both modes walk a tactic-conditioned state graph and use compatible logging contracts, so a mode switch changes execution dynamics without changing what downstream analysis reads.
In centralized mode, a single global selection loop owns frontier choice and expansion order. This gives one policy view over one queue, which is useful when you want minimal coordination effects and a clean single-agent baseline.
In distributed mode, multiple local agents operate over a shared frontier. Inflight reservations are used to reduce duplicate expansion pressure, and scheduling controls let us perturb coordination directly: block, delay, reroute, virtual loss, and depth/path bias interventions change who explores what and when.
Those scheduling interventions are deliberate lesions on search dynamics and let us ask whether solve behavior depends on one narrow expansion regime or remains robust under controlled changes in local-global coordination.
Both modes emit compatible tree and trace artifacts, so comparisons can stay within the same analysis contract (*_mcts_tree.json, traces, run summaries) instead of requiring mode-specific postprocess logic.
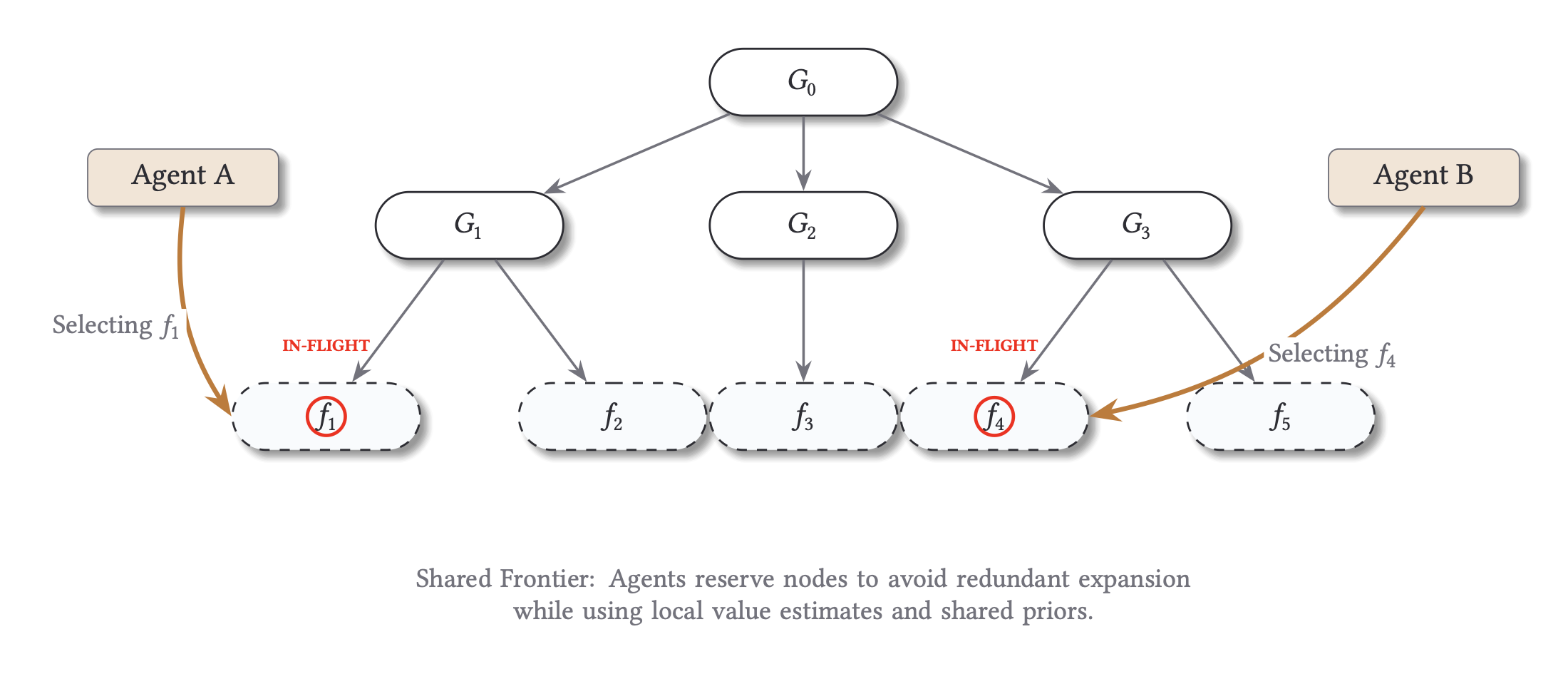
How to read the figure: each worker lane represents local agent activity against a shared frontier; reservations and scheduler policy shape contention and handoff. Dense synchronized bands suggest strong coupling, while staggered bands indicate looser parallel exploration.
5. Multi-Backend Surface
We use a multi-backend harness to measure if behavioral patterns appear across different backends or could be only implementation artifiacts.If it recurs across backend families with different proof objects and trace surfaces, the pattern is a stronger candidate invariant.
wonton-soup currently supports five execution backends:
leancoqevampirez3
Run-level schemas are shared (run_config.json, run_status.json, summary.json.gz), and backend-specific capabilities are explicit via run_status.json flags plus file-presence checks. That means a downstream consumer can fail loud on unavailable artifact families instead of guessing.
This contract matters for mixed analyses. For example, ged_search_graph is meaningful only when a true search graph exists; external solver traces may map to ged_trace_graph or proof-object families instead. Capability flags and validity metadata keep those distinctions visible.
Backend Artifact Families (Typical)
| Backend | Search-graph family | Proof family | Trace family | Practical note |
|---|---|---|---|---|
lean |
ged_search_graph |
proof-term artifacts when enabled | MCTS traces | Full search-graph comparisons are strongest here. |
coq |
usually unavailable | proof object family (integration dependent) | backend trace varies | Treat proof/trace availability as capability-gated. |
e |
unavailable | proof object family | ged_trace_graph from TSTP-style traces |
Mark trace completeness explicitly. |
vampire |
unavailable | proof object family | optional trace family | Proof-centric comparison is typical. |
z3 |
unavailable | proof object family | optional trace family | Search-graph GED is not the primary signal. |
Cross-backend comparisons are safest on shared run-level outcomes and explicitly labeled metric families. Structure-level comparisons should be grouped by compatible artifact families, not collapsed into one undifferentiated score.
Showcase
We pin two high-signal views used repeatedly in analysis: attractor separation and blind-relative efficiency.
6. Metrics Surface
We use a metric stack, not a single score:
- K-style search efficiency (
k_search_efficiency) from trace-derived blind nulls. - Paper-style paired blind baseline (
paper_k) from basin runs with--basin-blind. - GED families (
ged_search_graph,ged_search_graph_soft,ged_proof_graph,ged_trace_graph) with explicit validity metadata. - Trajectory comparison (divergence, reconvergence, recovery iterations).
- Basin analysis (solve rate, structure hash diversity, dominant basin frequency).
- Sheaf analyses (equivalence consistency and tactic-transform residuals).
- Cross-run lake exports for reproducible, cross-experiment aggregation.
Quick Metric Interpretation
| Metric | What changed in the intervention run | How to read it |
|---|---|---|
k_search_efficiency / paper_k |
Attempted edge count before first solve () vs blind baseline () | Higher is better; means fewer attempts than blind |
normalized GED_search |
Search-graph structure relative to wild-type | Near 0 means structurally similar search; larger values mean stronger reroute |
| shared prefix | Number of early wild-type steps replayed before divergence | High prefix means late divergence; low prefix means early policy/path change |
| divergence iteration/depth | First step where intervention path differs | Lower means early structural perturbation; higher means late perturbation |
| solve status under block | Whether constrained run still reaches terminal proof | Distinguishes robust reroute from true tactic dependency |
| basin mass + attractor ID | Fraction of seeds ending in each clustered trajectory family | Concentrated mass indicates stable basin; split mass indicates multimodal behavior |
K is reported as:
Example calibration: (about fewer attempts than blind).
- : attempted tactic edges until first terminal solve in the observed search graph.
- : expected attempted edges for a matched blind null policy over the same action surface.
- : orders-of-magnitude efficiency over blind (
K > 0is better than blind).
Two related outputs:
k_search_efficiency: trace-derived null model from postprocess.paper_k: paired blind baseline from basin runs with--basin-blind.
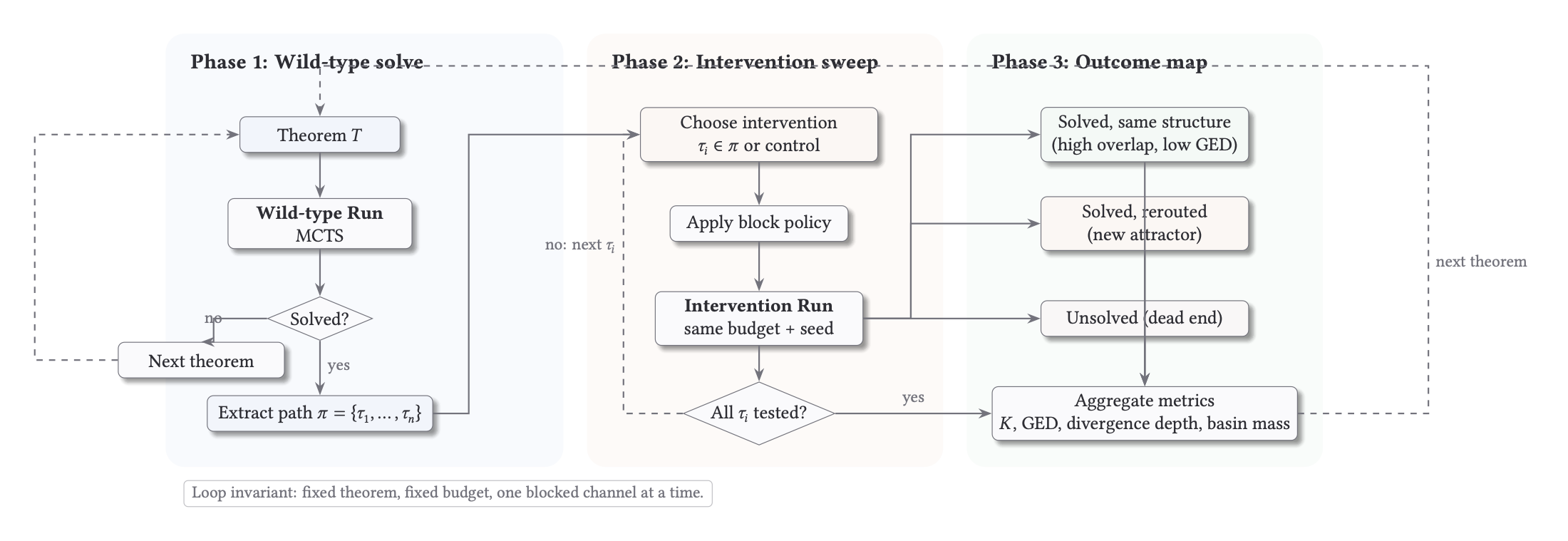
7. Intervention Protocol
For each theorem, we first solve a wild-type run and extract the solution path . We then run controlled lesions by blocking one tactic (or tactic family) from that path and rerun under the same budget and configuration.
This gives a clean comparison: same theorem, same search budget, one constrained action channel, repeated across all path tactics.
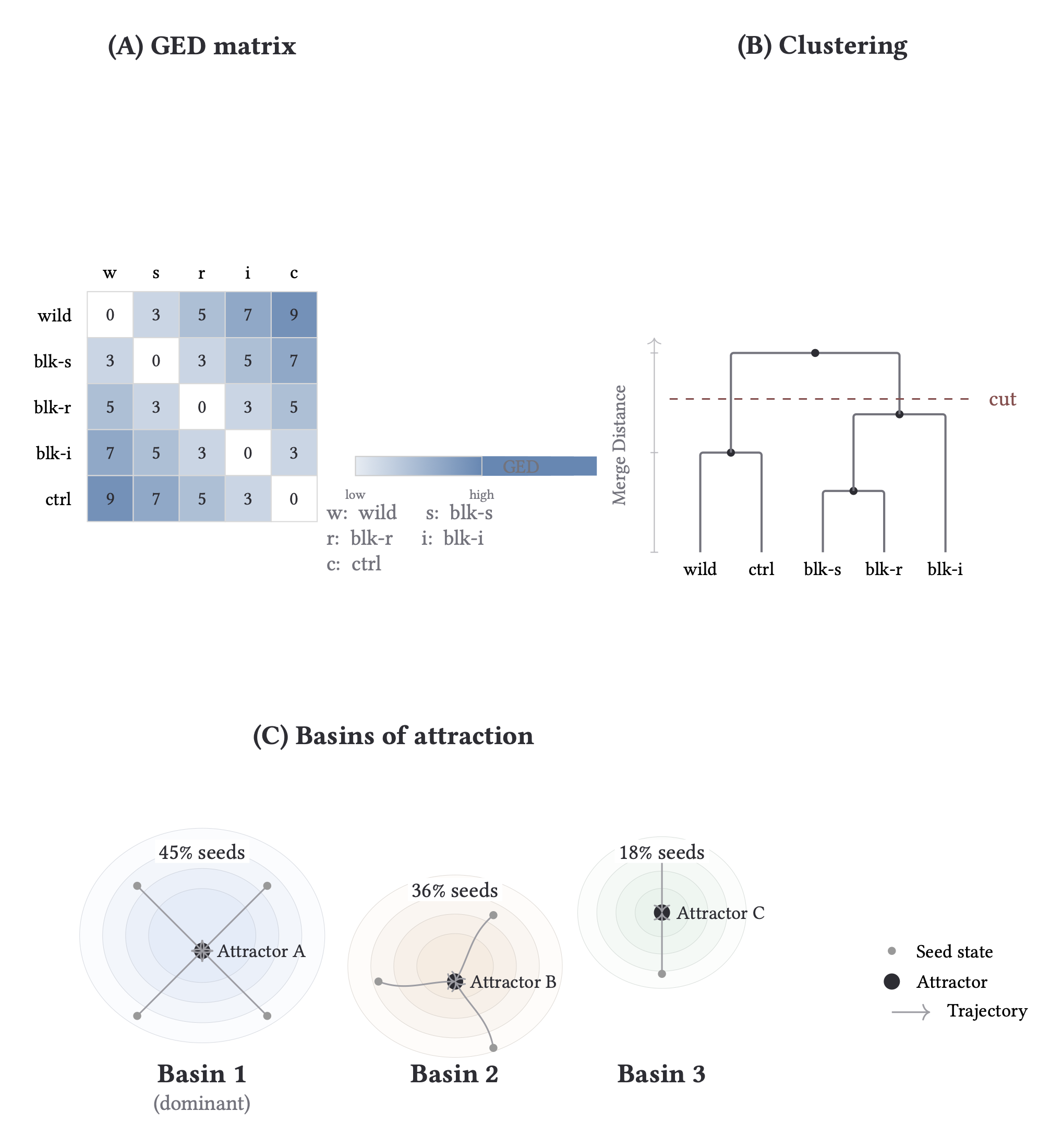
How to Read Attractor Analysis
- Panel A (GED matrix): pairwise structural distance between runs.
- Panel B (clustering + cut): where we place the cut determines attractor families.
- Panel C (basins): seed mass captured by each attractor family.
Interpretation: low GED + large shared basin mass implies robust proof structure; high GED with split mass implies genuine rerouting under intervention.
8. Log-Derived Vignettes
Vignette Gallery Player
Interactive graph gallery requires JavaScript.
A. Alternate Tactic at Same Structure
From a recent February corpus sweep:
control_null: solved, normalized GED0.00.block_intros: solved, normalized GED0.45.block_split_ifs: unsolved, normalized GED0.57.
Interpretation: one theorem shows both outcomes we care about. Some lesions reroute and recover, while others collapse. The split between GED=0 replicate and GED>0 reroute/collapse appears inside a single local intervention family.
B. Different Theorems, Different Intervention Patterns
From 2026-02-04:
contrapositive: blockcontrapose!solved, normalized GED0.67.nat_succ_pred: blockpositivitysolved, normalized GED0.00.iff_intro: blockexactsolved, normalized GED0.00.
Interpretation: blocking contrapose! forces a forward proof via intro, flipping the intermediate goal from to before discharge.
Interpretation: this is a local tactic swap: the proof keeps the same goal sequence but replaces an automated step with a direct lemma.
Interpretation: this is a shallow reroute; the structure is intact but the terminal discharge uses a different tactic.
9. Speculative Reach
This is an early slice from one primary provider and one MCTS policy family. The statements below are working hypotheses: grounded in current runs, intended to be pressure-tested as corpus and backend coverage expands.
A. Proof space appears multistable
Under fixed prover, encoding, and budget, a nontrivial subset of theorems admits multiple recurrent proof families: trajectory clusters that different seeds and interventions converge to. We treat these as empirical basins: GED-clustered families with meaningful mass under a fixed perturbation protocol. In several cases, families are clearly separated in structure, not just notation.
This mirrors a pattern seen in morphospace: a planarian genome does not encode one anatomy, but a landscape of stable anatomies selected by conditions and perturbations. In our setting, basins look like stable features under the tested protocol, not artifacts of single trajectories.
B. Constraint can generate competency
In multiple cases, tactic-block intervention solves a theorem that matched wild-type search does not solve under the same budget and seed settings. set_inter_self remains a clear example: blocking common high-prior tactics can redirect search into basins the unconstrained policy does not visit within budget.
Zhang et al. report an analogous effect in sorting: targeted local damage can improve global outcomes in decentralized dynamics. In both settings, constraint can increase solve probability on a meaningful subset of problems by forcing alternate structure.
C. Search efficiency is cognitive content, not metaphor
When , search is more efficient than blind tactic enumeration; larger positive indicates stronger savings over blind baselines. This follows the same functional form used by Chis-Ciure and Levin (2025): blind cost over observed cost, on a log scale.
Cross-substrate comparability depends on null-model calibration to each action surface. That calibration is active work. If calibration holds, proof search and biological systems can be compared on a shared efficiency axis.
D. Proof structures may be discovered rather than constructed
When wild-type runs, tactic blocks, and seed variation repeatedly converge to the same proof family (low internal GED within a basin), that pattern is less plausibly solver-specific. A practical interpretation is that search acts as an interface to an underlying structural family.
This is aligned with the TAME thesis: persistence under perturbation is the key signal. If the same family recurs across controlled perturbations, that family behaves like an invariant of the tested policy space.
E. Substrates may function as pointers
Multistability, lesion robustness, and measurable efficiency over blind search appear in regenerating planaria, self-sorting arrays, and MCTS proof search under interventions. The microphysics differ; the operational signatures are notably similar.
Our current hypothesis is that pattern-level structure is primary and substrates are interfaces through which that structure is expressed. Whether this reflects a deep principle or a measurement coincidence remains open, and testable.
Next steps: cross-backend basin agreement tests, calibrated estimation with matched null models, and wider corpus and provider coverage.
This is a technical draft for the Specter Labs research blog. For a compiled dashboard of selected runs, visit the Wonton Soup Dashboard.